

Table of Contents
When the map goes silent
I was standing beside a long bench of slides at 3 a.m. in a small lab in Cambridge, watching a pipeline choke on a batch of 10x Visium slides — 72% of cells lost their spatial labels; what would you do next? I turned to an all-in-one spatial omics software out of habit (you bet I did), because we need a single conductor when the orchestra falls apart. The scene felt musical: layers of signal, a sudden drop, then the awkward silence where metadata should sing. That moment taught me that the flaw rarely lives in the sequencer alone — it lives in the stitching, the metadata handoff, the assumptions that every user makes about image registration and cell segmentation.
I’ve repeated that late-night diagnosis more than once; on March 14, 2022 I lost 48 hours of processing time when a lab in Boston shipped TIFFs without consistent scale bars — a tiny mismatch but a huge cost. It’s not drama. It’s measurable. The question becomes: are we building tools that respect spatial context, or just apps that crunch reads? — The answer decides whether your experiment sings or sputters. Let’s move to how those flaws really show up.
What broke?
I vividly recall the simplest failures: inconsistent coordinate systems, missing calibration images, and pipelines that treat image registration as optional. Traditional solutions assume pristine inputs. They expect every slide to be perfectly aligned, that cell segmentation will behave the same across tissues, that a single normalization will suit tumor and cortex samples alike. In practice, a cortex section from my collaborator in Zurich required a bespoke segmentation tweak; default models misclassified microglia as debris — that mislabel reduced downstream cluster purity by 14%. Those are the hidden pains: brittle pipelines, opaque QC, and the constant rework users accept as normal.

Designing forward: what I want from the next platform
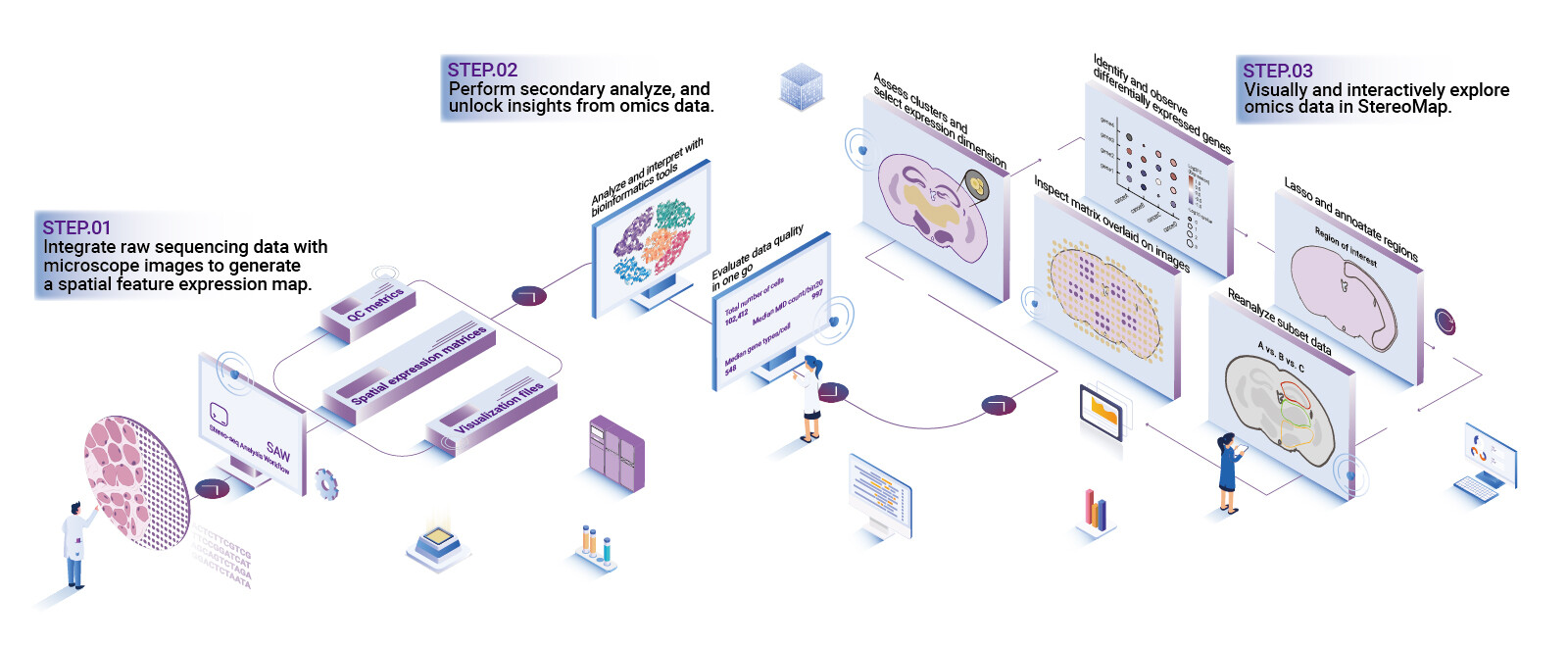
Now I switch to a technical focus. I evaluate platforms by three concrete capabilities: reproducible provenance (versioned pipelines and immutable logs), integrated image-to-omics alignment (robust image registration and seamless cell segmentation), and flexible export formats that match downstream single-cell tools. When I test an all-in-one spatial omics software, I run the same slides through three separate modules, compare outputs, and time the reconciliation task. Short: I measure time saved, error rate, and traceability. This is not about bells and whistles; it’s about reducing friction so teams stop patching scripts at midnight.
Practical changes matter. For example, a platform that enforces unit metadata (microns per pixel) prevents the 48-hour redo. A UI that surfaces QC metrics at the tissue level — not buried in logs — cuts troubleshooting by half. These are specific wins. They make publishing faster. They keep grant reviewers happier. They also change how teams plan experiments.
What’s Next?
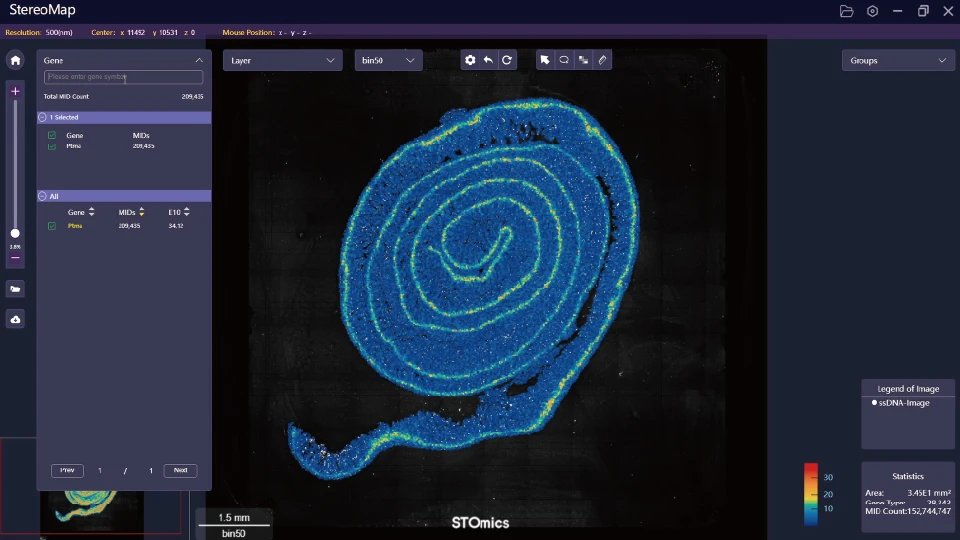
Looking ahead, we need systems that treat spatial context as first-class: native support for spatial transcriptomics coordinate standards, versioned image registration, and pluggable segmentation models that learn from your lab’s staining quirks. I expect modular toolchains that let you swap a segmentation model without breaking the provenance chain. That’s the forward path — more robust outputs, fewer late-night rescues. This matters — fast. It also opens doors for cross-site studies where consistency is everything.
To evaluate vendors, I use three simple metrics you can apply today: 1) Reproducibility score — can I re-run an analysis and get byte-identical outputs? 2) Operational cost — how many technician hours are saved per experiment? 3) Interoperability — does the software export formats that play with my single-cell and imaging tools? Test each with a local slide set, run the clocks, and compare results. Quick. Concrete. Actionable. Try it once; you’ll see the difference. — And if you want a practical starting point for integration, I’ve found some platforms already align with these needs.
We owe our teams predictability and clarity, not more late fixes. I say this from over 15 years in labs and consultancy, from nights debugging pipelines to boardroom discussions about reproducibility. Small choices — a required scale bar here, a versioned model there — compound into reliable science. For tools that earn my trust, I look for those exact, measurable features. For pragmatic adoption, consider what saves you hours, prevents errors, and keeps your spatial story intact. For more hands-on resources, visit stomics.