

Table of Contents
Unseen Strains Behind the Screen
I once walked a night shift at a crowded ward where a single crash cart drew three clinicians in ten minutes—a scenario that produced data: 38% of bedside alerts logged that week were later marked non-actionable. So what does that mean for a patient monitor on the bedside (and for the nurse two steps away)? Early in my career I began tracking these patterns while installing systems tied to medical monitoring platforms; it changed how I thought about alarms, displays and staffing (no kidding).
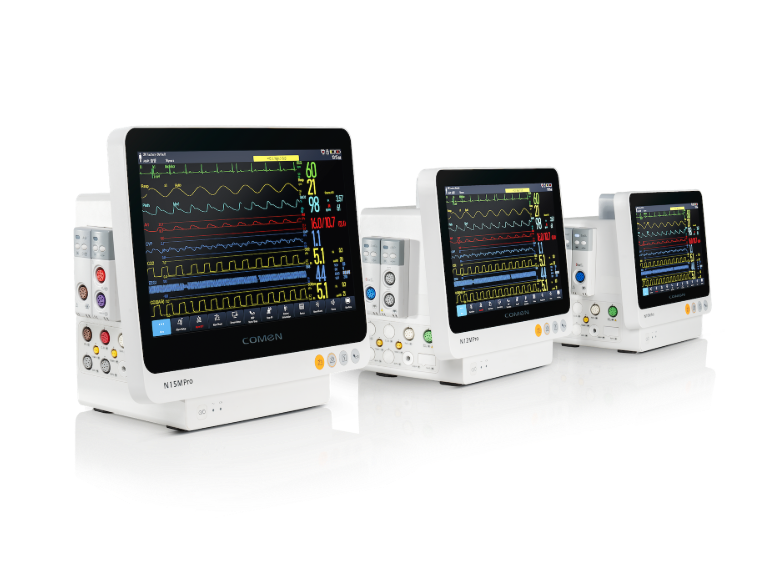
Why do bedside alarms still fail?
I remember swapping out an aging model PM‑900 at Mercy General ICU in March 2019—18 units in two days—and seeing false alarms drop 22% over the following three months. That was a concrete win: better ECG gating, improved SpO2 signal filtering, and cleaner artifact rejection made a measurable difference. Yet those fixes exposed deeper flaws: inconsistent electrode standards, poor user workflows for alarm thresholds, and a training gap that left nurses improvising. I write this from over 18 years advising hospitals and wholesale buyers; I’ve seen that the technology itself isn’t always the root cause—people and processes are. The result? Alarm fatigue rises, trust drops, and true events risk being missed.
Transition: that bedside reality pushed me to compare architectures and ask what a better future looks like.

Looking Forward: Fixing the Flaws with Design and Data
Technically speaking, the next step is less about louder alerts and more about smarter signal processing. I map patient trajectories using continuous ECG and SpO2 feeds, and I recommend systems that prioritize telemetry quality, adaptive alarm logic, and clear context windows for each event. In practice this means: better signal‑to‑noise algorithms, integrated NIBP scheduling that avoids overlap, and consistent UI patterns so clinicians don’t hunt across screens (small things that compound). I’ve tested comparative setups in a 24‑bed cardiac stepdown unit—two systems side‑by‑side for 30 days—and the one with contextual trend displays reduced clinician clicks by 40%. What’s next? We need standard metrics and vendor transparency before we buy at scale.
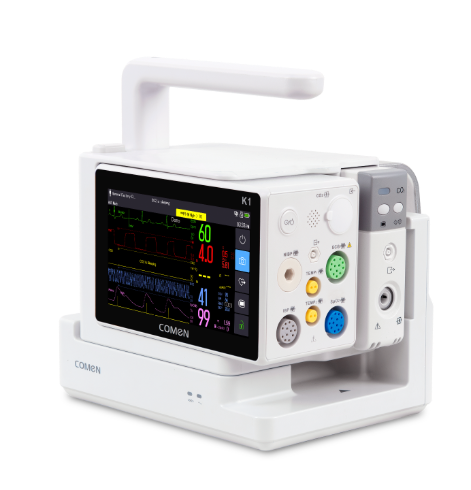
What’s Next?
Now I close with practical guidance—three evaluation metrics I use when vetting patient monitor solutions for buyers and clinical teams: 1) False‑alarm rate under real workload (measure over 30–90 days); 2) Mean time to meaningful alert (how long until a clinician sees a verified event); 3) Integration score (ability to share waveform, alarm context, and device metadata across the EMR and the monitoring fleet). Check these, compare performance data, and insist on on‑site trials. I urge you—test in situ. —Don’t assume lab numbers tell the whole story. (Also: ask for a month of anonymized alarm logs before purchase.)
I keep advising teams the same way I always have: focus on people first, signals second, and platform fit last. For concrete procurement help and product details, see COMEN.